December 2024
This paper provides a detailed reflection on Ilya Sutskever’s NeurIPS 2024 presentation titled "Pre-Training as We Know It Will End". The talk highlights significant shifts in artificial intelligence methodologies, emphasizing the diminishing utility of current pre-training strategies and the importance of evolving approaches to scaling and data generation.
As an AI-focused research organization, DLYog Lab Research Services LLC presents an analysis of the insights shared during the talk, including the successes of autoregressive models, the role of GPU parallelization, and the challenges with LSTMs and data constraints. We explore the implications of these ideas, contextualized through the lens of scaling laws and biological analogies. Our discussion integrates both agreement with the speaker’s perspective and additional reflections on future directions.
Visualizations and examples, inspired by the presentation, are provided to complement the analysis and support a broader understanding of the subject. This paper seeks to contribute to the ongoing dialogue on the future of AI training methodologies and the path forward as outlined by Ilya Sutskever.
Ilya Sutskever’s presentation at NeurIPS 2024 explored the evolving landscape of AI, urging researchers to reconsider the long-standing reliance on large-scale pre-training. As the field expands, the methods once hailed as breakthrough strategies—such as massive data collection and purely scaling autoregressive models—face mounting limitations. These constraints arise not only from data scarcity but also from the economic and environmental realities of sustaining ever-increasing compute demands.
The talk highlighted three interconnected themes shaping the future of AI research:
Finite Growth of Data: The once-exponential increase in web-scale datasets appears to be leveling off, intensifying the need for synthetic data generation and more diverse data curation.
Compute Power and Scaling: GPU parallelization and distributed training have enabled larger models, but hardware progress alone cannot resolve fundamental data bottlenecks and inefficiencies in training pipelines.
Biological Inspirations: By drawing analogies to mammalian brain evolution, Sutskever underscored the importance of optimizing learning processes within constrained resources.
Sutskever’s pronouncement that “pre-training as we know it will end” is not a dismissal of past success, but rather a pivot toward new methodologies. Emphasis on synthetic data generation, meta-learning, and more nuanced model architectures reflects a broader paradigm shift. Whether through advanced model compression, in-context learning strategies, or biologically inspired energy-efficient designs, AI practitioners are now compelled to think beyond conventional pre-training regimes.
In this paper, we build upon these ideas by revisiting the successes and pitfalls of current approaches while offering reflections for future innovations. We examine the scaling hypothesis, GPU-driven breakthroughs, and the shortcomings of architectures like LSTMs, tying them all back to the core message of rethinking AI training from the ground up. Through detailed analyses and visual demonstrations, we aim to translate these insights into practical roadmaps for synthetic data production, resource-efficient architectures, and ethically aligned AI systems.
Ultimately, our goal is to place Sutskever’s presentation within the broader continuum of AI’s rapid evolution. By integrating lessons from biology, addressing data constraints head-on, and revisiting established scaling laws, we hope to illuminate a path that balances computational feasibility, ethical considerations, and the pursuit of ever-smarter AI.
One of the central points Sutskever raised was the resounding success of autoregressive models—exemplified by GPT-like architectures—that have reliably improved with more data and bigger model sizes. This phenomenon supports the so-called “scaling hypothesis,” where systematic increases in compute and training data generally yield superior outcomes. The transformative impact of this hypothesis has been most evident in natural language processing, where vast internet-scale corpora enable broad transfer learning with minimal task-specific fine-tuning.
Notably, autoregressive models’ iterative nature allows for stepwise generation and refinement, which has proven valuable in tasks ranging from open-ended text generation to code completion. The “bigger is better” approach has guided research and industry alike, reinforcing the notion that large-scale training remains effective, at least within current compute and data boundaries.
The talk also underscored the importance of GPU-based parallelization and distributed training frameworks. Early experiments assigning different parts of a neural network to separate GPUs—layer splitting, model parallelism, or pipeline parallelism—demonstrated how multi-GPU configurations can drastically reduce training time. One example Sutskever shared featured an 8-GPU system that realized a more than 3x speed boost over single-GPU setups by carefully distributing softmax and other memory-intensive computations.
This milestone not only solidified parallelization techniques as a cornerstone of modern AI but also illustrated how hardware and algorithmic optimizations must advance in tandem. As new architectures and larger models emerge, distributed training strategies will remain crucial to efficiently leveraging available compute. The ability to scale seamlessly with future hardware is paramount, ensuring that scaling laws continue to hold in practice—even as we look toward more data-efficient paradigms beyond today’s pre-training approaches.
An important retrospective from Sutskever’s talk involved revisiting the dominance of Long Short-Term Memory (LSTM) networks in the earlier stages of deep learning. While LSTMs revolutionized sequence modeling by mitigating the vanishing gradient problem, they now appear less capable of handling the long-range dependencies and parallelization demands of modern large-scale tasks. As models balloon in size and complexity, recurrent architectures like LSTMs struggle to keep pace, owing to their intrinsic sequential processing and limited flexibility in capturing context over extended spans of data.
These limitations became particularly apparent when Transformers, with their attention mechanisms, started delivering superior results. The shift away from LSTMs exposed inherent scaling drawbacks—issues that were invisible at smaller data scales but glaringly obvious when training on web-scale corpora. The present challenge, therefore, is to recognize both the historical significance of LSTMs and the necessity to push beyond them as we seek new frontiers in efficient, scalable architectures.
Another dimension of “what went wrong” pertains to the assumption that ever-growing datasets would always be readily available. Sutskever’s talk likened data to the “fossil fuel of AI”—an initially abundant resource that may become scarce or impractical to harness at scale. Web-scale data repositories, while enormous, also suffer from duplication, bias, and diminishing returns for model improvement. Overfitting on repetitive or skewed data can mislead the performance gains we associate with purely scaling up.
Moreover, for highly specialized or emerging domains, curated datasets can be small and expensive to acquire, limiting the utility of brute-force pre-training. This inherent mismatch between compute growth and data availability has forced the community to look toward techniques like synthetic data generation, active learning, or more data-efficient architectures. Recognizing the flawed assumption that “more data is always out there” is a vital first step to charting alternative pathways for future AI research.
Sutskever’s central contention—that “pre-training as we know it will end”—reflects a growing realization that current large-scale data paradigms have finite mileage. One suggested pivot involves broader reliance on synthetic data generation. Rather than relying on static, internet-based corpora, synthetic data pipelines could yield richer and more controlled training sets, mitigating both scalability and bias concerns. Industries like autonomous driving and robotics already benefit from realistic simulations, demonstrating how well-crafted synthetic tasks can accelerate model mastery of difficult edge cases.
Coupled with the question of training is inference: how to best deploy these expanded or newly conceived models. Sutskever’s presentation touched on a shift away from computationally expensive inference stacks toward more adaptable and resource-aware strategies. This could involve pruning, quantization, or leveraging specialized hardware that can dynamically allocate resources based on context. Streamlining inference has become as important as training itself, particularly for cost-sensitive or latency-critical applications like real-time language translation and robotics.
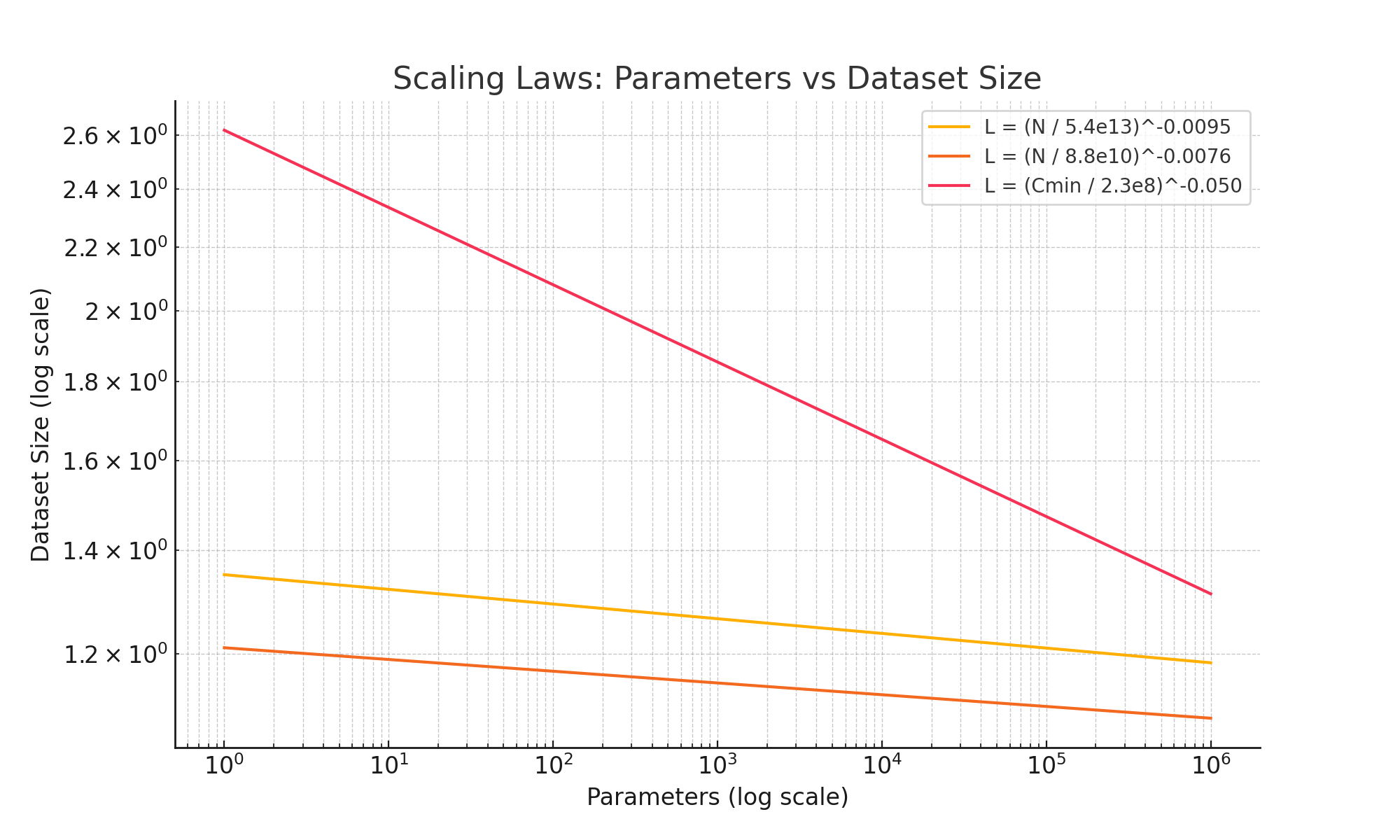
Sutskever’s talk delved into the crucial role of scaling laws, which suggest that performance generally improves as models and datasets grow in size. However, simply pushing these parameters to their limits is not without caveats—diminishing returns, data scarcity, and prohibitive compute costs temper the unbridled “bigger is better” mentality.
Still, these laws serve as a valuable heuristic: they demonstrate how, at scale, certain architecture or training decisions can yield outsized improvements. Sutskever emphasized that although scaling laws outline an upward trajectory, the industry must be alert to resource bottlenecks like limited high-quality data and sustainable compute infrastructure. The emergence of synthetic data, optimized architectures, and specialized hardware each offer potential avenues for transcending the plateau.
In short, scaling laws remain an important compass guiding AI’s progress, but the community increasingly recognizes their limitations when confronted with real-world constraints. Balancing raw scale with more ingenious strategies—like synthetic data generation, meta-learning, or energy-efficient model designs—represents the next frontier, ensuring that AI’s growth remains both powerful and practical.
Finally, Sutskever reiterated the fertile parallels between biological evolution and AI design. Just as the mammalian brain scales within metabolic constraints, AI models must optimize memory, computation, and energy usage without sacrificing performance. This line of reasoning not only draws inspiration from biology’s efficient architectures but also underscores the potential for greater synergy between neuroscience, cognitive science, and deep learning as we grapple with the bottlenecks ahead.
Biological systems, particularly those of mammals, offer valuable insights into the design and scalability of artificial intelligence. By examining how organisms have evolved to balance efficiency, adaptability, and constrained resources, researchers can draw parallels for creating more sustainable and robust AI models.
One key parallel is the relationship between brain size and intelligence, often following a power-law distribution. Incremental increases in brain mass can yield disproportionate gains in cognitive capabilities—a trend reminiscent of AI’s scaling hypothesis. Sutskever suggested that understanding these biological scaling principles can inform how we design and expand AI models without simply relying on brute-force parameter growth.
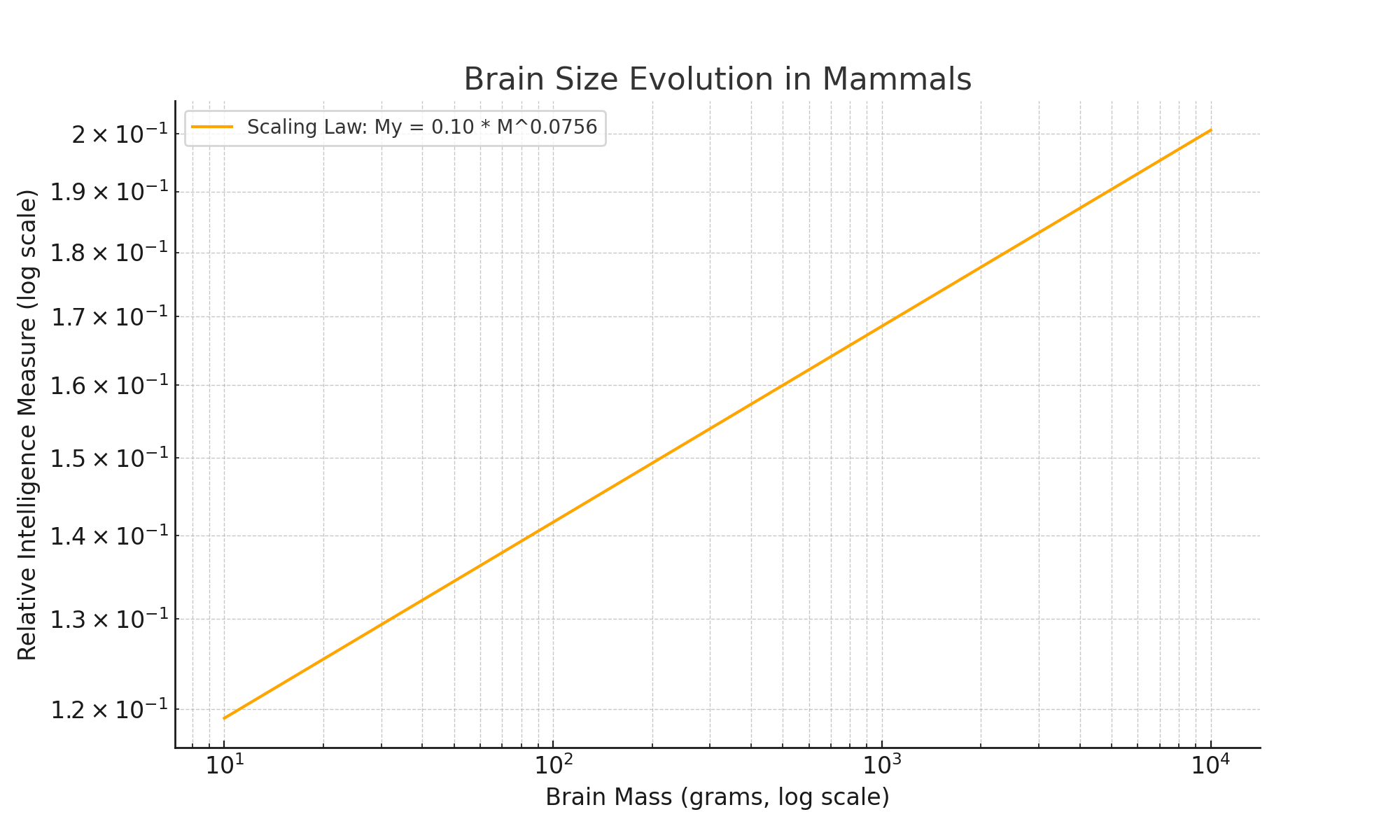
Biological neurons operate at minimal energy consumption relative to their processing power. Emulating such efficiency in AI could involve model compression, dynamic inference, and adaptive learning strategies. These biologically inspired approaches aim to reduce compute without sacrificing accuracy, highlighting that mere size is not the sole driver of performance.
The mammalian brain’s evolution reflects trade-offs—energy expenditure vs. enhanced cognitive function. By analogy, AI research must consider practical constraints (like training costs, carbon footprint, and hardware limits) when scaling models. Techniques that balance these factors—pruning, conditional computation, or mixture-of-experts—can make large models more sustainable while retaining their capabilities.
Just as mammalian brains evolved hierarchical and distributed processing structures, future AI could adopt architectures that adapt to changing environments and tasks. Sutskever’s perspective aligns with these natural principles, suggesting that AI models must become more context-aware, resource-efficient, and dynamically reconfigurable to flourish in the post-pre-training era.
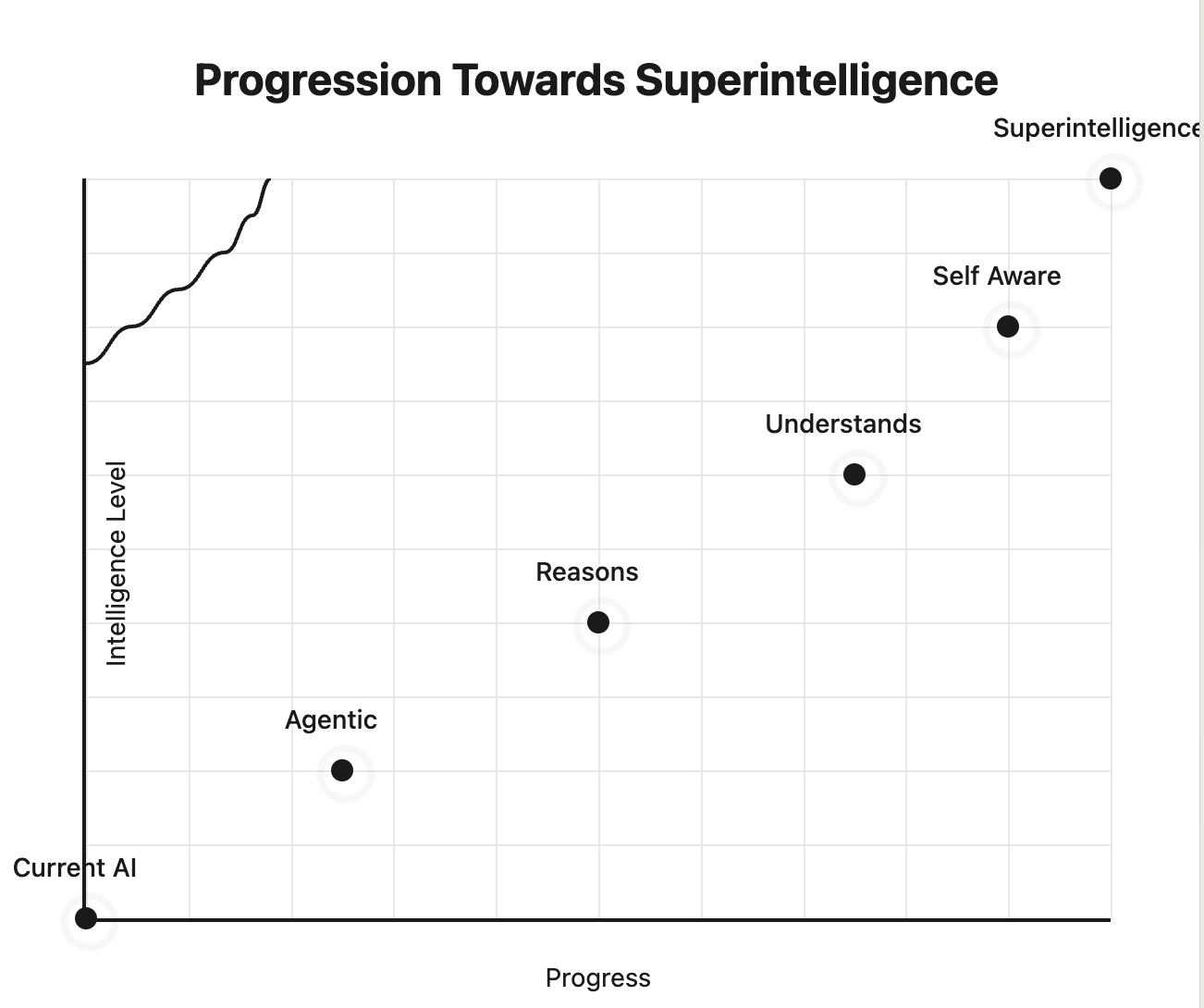
The discussion of the future of artificial intelligence inevitably leads to the concept of superintelligence, a state where AI systems surpass human cognitive capabilities across all domains. Ilya Sutskever highlighted several key attributes that define this level of intelligence:
Agentic: A superintelligent system would exhibit autonomous decision-making capabilities, proactively acting to achieve goals with minimal human intervention.
Reasons: It would possess the ability to reason logically and infer solutions to complex, unstructured problems, akin to human-level critical thinking but with superior speed and accuracy.
Understands: Understanding, beyond statistical correlations, implies grasping concepts, intentions, and causal relationships, thereby enabling meaningful generalization.
Self-Awareness: A superintelligent system may reach a level of self-awareness, reflecting on its own state, actions, and goals, leading to a form of introspective reasoning.
The emergence of superintelligence raises both unprecedented opportunities and challenges. On the one hand, such systems could accelerate scientific discoveries, solve global crises, and usher in a new era of technological progress. On the other hand, the development of agentic, self-aware systems introduces significant ethical and existential concerns, including:
Control and Alignment: Ensuring superintelligent systems align with human values and intentions remains an unsolved challenge. Misalignment could lead to unintended or catastrophic consequences.
Autonomy and Decision-Making: Superintelligent systems with agentic behavior may act in ways that are unpredictable or incomprehensible to humans, raising questions of trust and accountability.
Impact on Society: The integration of superintelligence into society will disrupt economies, labor markets, and global governance, necessitating proactive policy frameworks to manage this transition.
While superintelligence remains a long-term prospect, the trajectory of AI advancements, as discussed in Ilya’s talk, indicates that this future may arrive sooner than anticipated. By addressing foundational challenges today, such as data availability, compute efficiency, and safety alignment, the AI research community can prepare for the transformative potential of superintelligent systems.
In concluding this reflection, it becomes evident that the AI community stands at a pivotal juncture. The successes of autoregressive models and GPU parallelization illustrate how scaling laws can serve as powerful catalysts for progress. Nevertheless, the looming constraints around data availability, computational cost, and model sustainability point toward an inevitable shift away from our current reliance on brute-force pre-training.
Sutskever’s forecast that “pre-training as we know it will end” speaks directly to a broader need for evolving AI development paradigms. Synthetic data generation offers a promising avenue to circumvent data scarcity, while biologically inspired design insights emphasize the value of energy-efficient, context-aware model architectures. In parallel, careful attention to ethics and safety is critical when grappling with the prospect of superintelligence, which may soon redefine the contours of human–AI interaction.
Equally important is acknowledging the singular nature of the internet as our principal data source for large-scale pre-training. This unique and finite reservoir of human-generated content has been instrumental in fueling the rapid ascent of AI capabilities. However, as AI systems increasingly partake in the creation of new data—whether through synthetic content generation or AI-augmented production—there is a growing risk of stagnation and self-referential feedback loops. While synthetic data helps to mitigate domain-specific scarcity, it relies heavily on existing patterns and therefore risks reinforcing biases or limiting truly novel innovations.
Consequently, the research community faces an imperative to diversify data creation and curation strategies. Human-generated content remains critical in fostering creativity and variation, while interdisciplinary collaborations and robust data stewardship can ensure that datasets remain both expansive and ethically grounded. By continuing to experiment with meta-learning approaches, dynamic inference strategies, and novel forms of model compression, researchers can chart a more sustainable, versatile path forward—one that balances the finite “one internet” reality with the drive for perpetual improvement and innovation.
This paper underscores that embracing both technological advancement and responsible data practices remains paramount to transforming pre-training methods and preparing for AI’s next horizon. Through a combination of synthetic and human-generated data, biologically inspired designs, and vigilant oversight of ethical and resource considerations, the AI community can stay on course toward ever more capable—and societally beneficial—intelligent systems.
We thank Ilya Sutskever and the NeurIPS community for their contributions to advancing AI.
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. arXiv preprint arXiv:1409.3215. DOI:10.48550/arXiv.1409.3215.
Sutskever, I. (2024). Sequence to Sequence Learning with Neural Networks. NeurIPS 2024 Presentation. YouTube Link.